Microsoft’s AI-powered assistant, Copilot Vision, has gained desktop screen scanning capabilities. With this new feature, Copilot can now analyze the entire screen image, not just specific apps. This feature is now available to users as part of the Windows Insider program.
Copilot Vision Offers Screen Scanning
Previously, Copilot Vision could only establish context across a limited number of apps. With the update, it now activates across the desktop or in any app or browser window selected by the user.
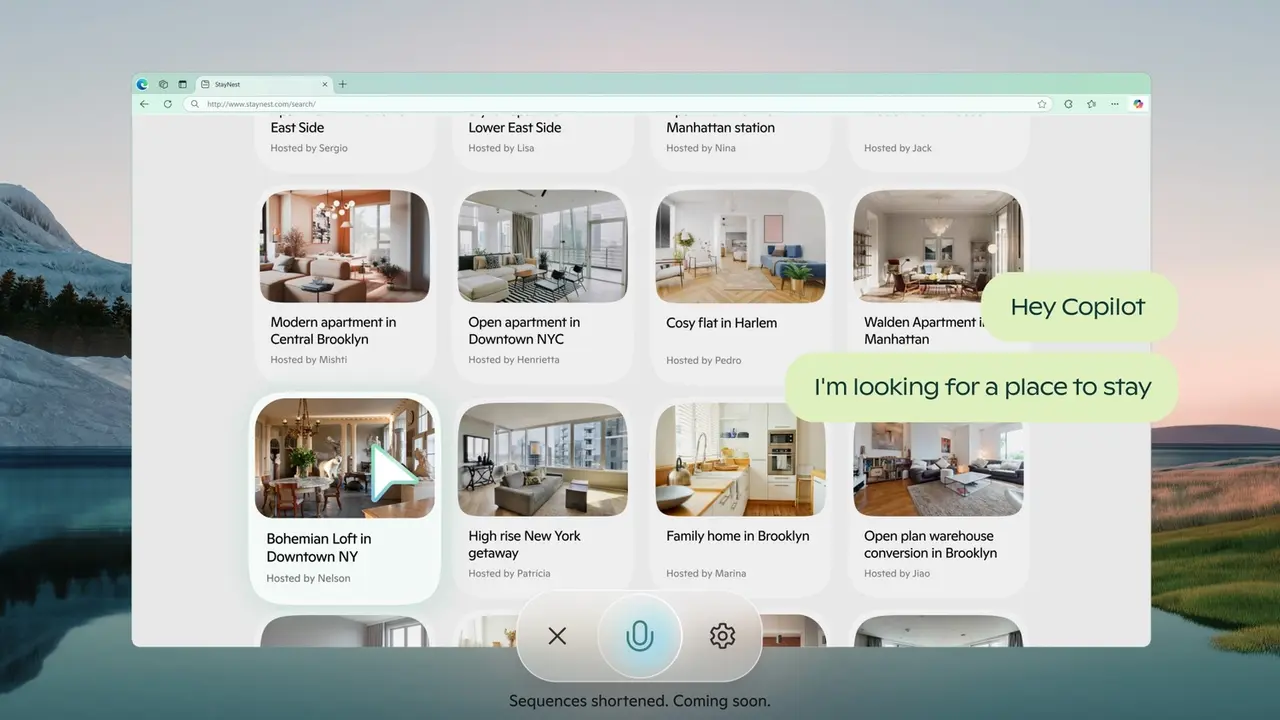
By clicking the glasses icon within the app, users can manually specify the screen area they want analyzed. The system operates on a screen-sharing basis, but only reads the image with user permission.
With the new version, Copilot Vision can perform contextual analysis based on the content it sees, offer suggestions, and provide voice guidance. For example, it can interpret a complex document, evaluate a graphic design, or receive step-by-step guidance during a game. Microsoft states that this feature can increase productivity, especially in creative projects, professional presentation preparation, or personal organization.
The system does not operate in a continuous recording mode. Copilot Vision is activated solely by user interaction and operates based on a snapshot. This approach, unlike Microsoft’s previously criticized Recall feature, operates without recording the screen in the background. This design approach highlights a design approach aimed at mitigating privacy concerns.
Copilot can also capture and analyze images from the mobile device’s camera. With this feature, AI can also provide assessment and guidance based on visuals from the physical world. For example, a faulty device part can be identified, or a document can be scanned and interpreted with the camera.
With the integration of Copilot Vision into the desktop, AI has become a much more interactive and visually based assistant for Windows users. The system accelerates access to information in daily computing and takes digital assistance to a new level by interpreting visual content.