

In a historic step forward for artificial intelligence, NVIDIA announced a massive English AI training database called Nemotron-CC. The new database contains a total of 6.3 trillion tokens, of which 1.9 trillion are synthetic data. NVIDIA said that this new database is one of the most comprehensive resources ever developed for training large language models (LLMs). The company said that this innovation will make a big difference, especially in academic and commercial fields. Here are the details…
NVIDIA introduces Nemotron-CC, a 6.3 trillion token artificial intelligence training database
The Nemotron-CC database was developed using a large amount of data from the Common Crawl platform. This data was put through a rigorous data processing and filtering process to create a high-quality subset, Nemotron-CC-HQ. NVIDIA says that this database is “ideal training material for large language models”.
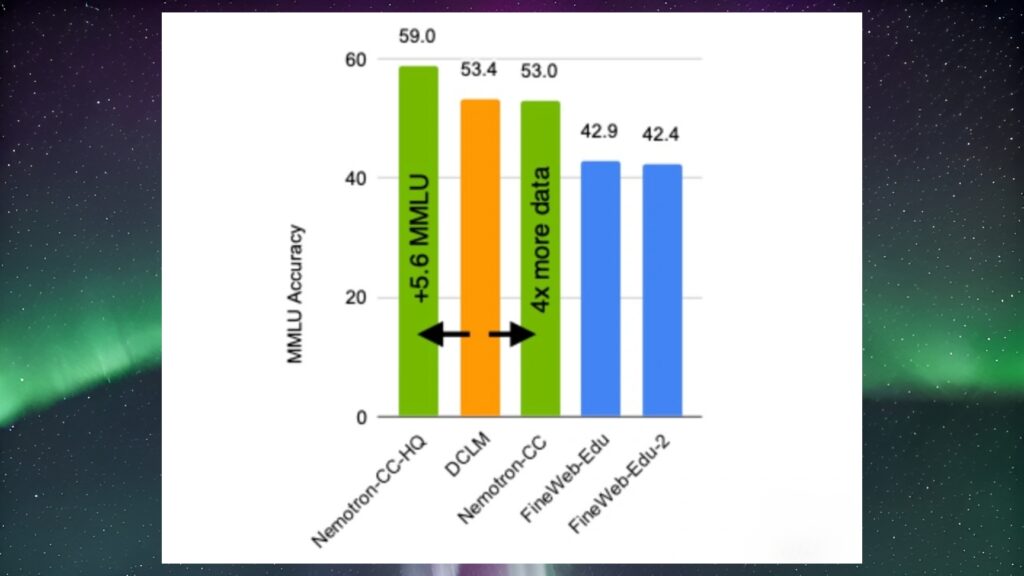
In fact, this innovation is expected to address the limitations of existing training databases in terms of scale and quality. In particular, it will offer superior performance compared to leading open source databases such as the Deep Common Crawl Language Model (DCLM). NVIDIA announced that models trained with Nemotron-CC have delivered notable improvements in several tests. For example:
- MMLU (Massive Multitask Language Understanding) tests improved by 5.6 points compared to existing systems.
- Models with 80 billion parameters improved by 5 points in MMLU tests and 3.1 points in ARC-Challenge tests.
- Nemotron-CC achieved an average performance improvement of 0.5 points on 10 different tasks compared to other high-quality databases.
Looking at the results, we can clearly see how Nemotron-CC can have an impact on the training and capabilities of large language models. In addition, NVIDIA announced that Nemotron-CC was developed using techniques such as model classifiers and synthetic data rephrasing. These techniques were used to increase the variety and quality of data in the database. They also increased the number of high-quality tokens by relaxing the strict rules of traditional data filtering methods.
NVIDIA has made Nemotron-CC available through the Common Crawl platform and announced that documentation for the database will soon be available on the company’s GitHub page. This will make it easy for both academics and commercial users to use the database. You can access the new database here.
What do you think the impact of this innovation will be on the future of AI technologies? You can share your views in the comments section below…










