OpenAI announced the new rendering capabilities of the GPT-4o model. According to the company’s statement, GPT-4o is capable of producing much more precise, detailed and realistic images than previous models. With this feature, users will be able to create and edit the images they want with simple commands or develop new designs based on existing images.
New era in visual creation with GPT-4o!
OpenAI has long advocated that visualisation should be a core skill for language models. GPT-4o, developed in line with this idea, is the company’s most advanced and useful visualisation system to date. The visuals created with GPT-4o are not only aesthetically pleasing but also very useful in terms of information transfer.

The new model understands the commands given by the users more accurately and applies them to the images more precisely. Especially in complex and multi-object images, GPT-4o performs better than its competitors.
For example, the model can now consistently combine 10 to 20 different objects in a single image. In addition, thanks to the model’s ability to correctly process text and symbols in images, it becomes much easier to produce informative visuals such as logos, diagrams, infographics.
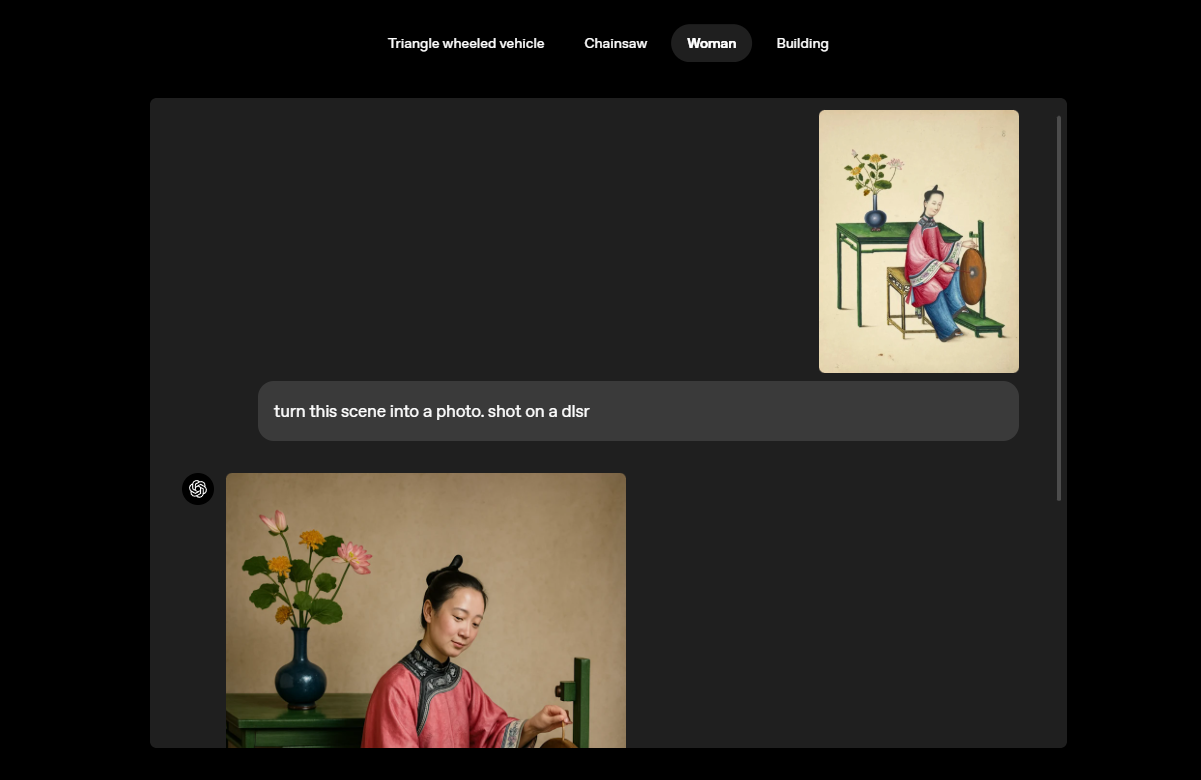
Examples shared by OpenAI include meeting notes on a whiteboard, comic books, detailed infographics of scientific experiments, and visuals supported by meaningful text. In the company’s statement, it was emphasised that visualisation should be used not only for decorative purposes, but also as a powerful tool for information sharing and communication.
The new GPT-4o model also features multi-step image generation. In this way, users can develop the images they create together with the model through a natural conversation. For example, the design of a game character can be shaped step by step and the consistency of the character can be maintained at each step.
GPT-4o also has the ability to analyse user uploaded images and derive new images from them. This feature makes the model a more intuitive and personalised tool for users. According to OpenAI, the variety and style of images used in the GPT-4o model allows the model to create photo-realistic images and perform visual transformations convincingly.
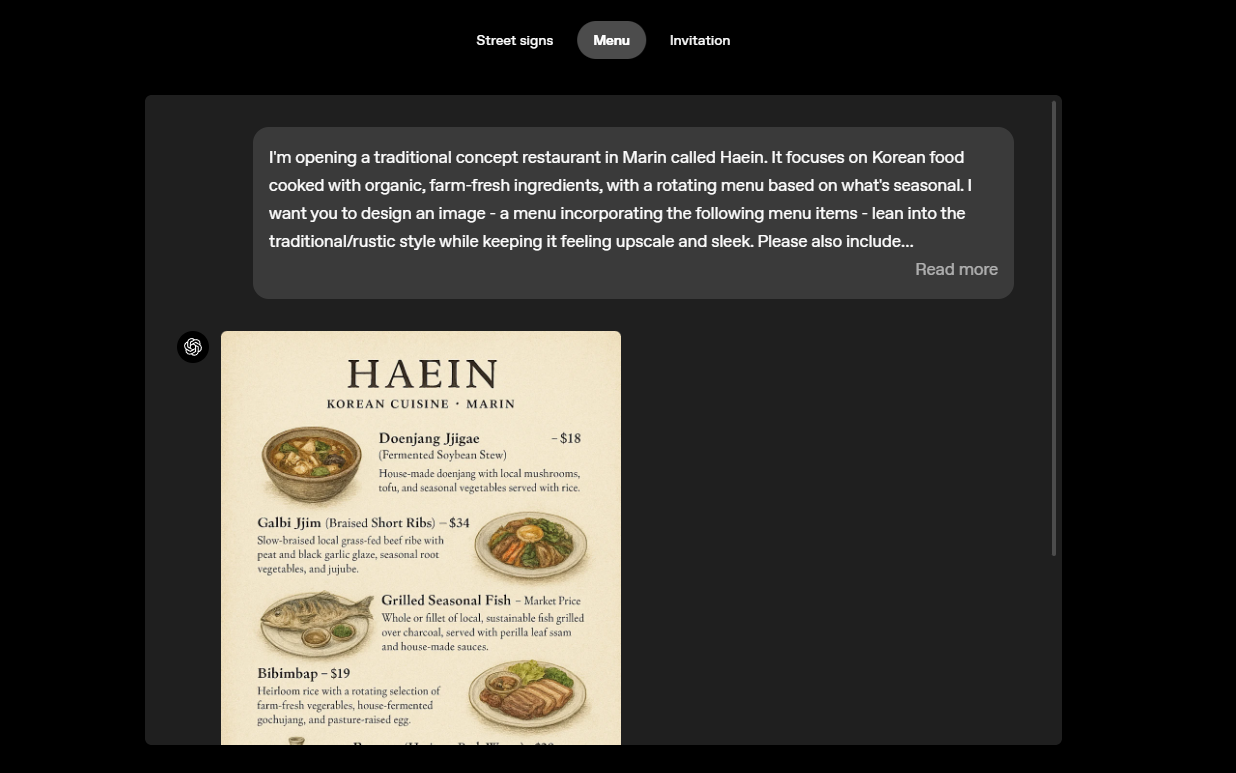
OpenAI acknowledges that the new model still has some limitations. In particular, there are limitations for information-intensive graphics with small text size or images containing multiple languages. It was also stated that sometimes problems such as unwanted image cropping and inconsistencies may occur. The company stated that improvements will be made on these issues in the future.
OpenAI also announced that it has taken various measures to secure the visual creation feature. C2PA metadata is added to all images produced by GPT-4o, indicating that the source of the content is OpenAI. In this way, the authenticity of the created content can be verified more easily. It was also emphasised that harmful content requests are automatically blocked.
As of today, GPT-4o’s visualisation features are available in ChatGPT as the default option for Plus, Pro, Team and free users. Enterprise and Edu users will also be able to benefit from this feature shortly.
For DALL-E lovers, this model will still be available through a special DALL-E GPT. Developers will also be able to use GPT-4o’s visualisation feature via API in the coming weeks.