NVIDIA Blackwell GPUs Cut DeepSeek v4 Inference Costs Fivefold

NVIDIA has achieved a significant milestone in artificial intelligence efficiency by reducing the processing cost per token for the DeepSeek v4 model by five times in just one month. Through a series of advanced software optimizations specifically engineered for its Blackwell architecture, the company has set a new benchmark for operational cost-effectiveness in the AI sector. By leveraging hardware units such as the GB200 and GB300, NVIDIA has demonstrated how strategic software-level tuning can maximize throughput. This development is expected to drastically lower operational expenses for enterprises running large-scale AI workloads while further solidifying NVIDIA’s dominance in the global hardware and software ecosystem. 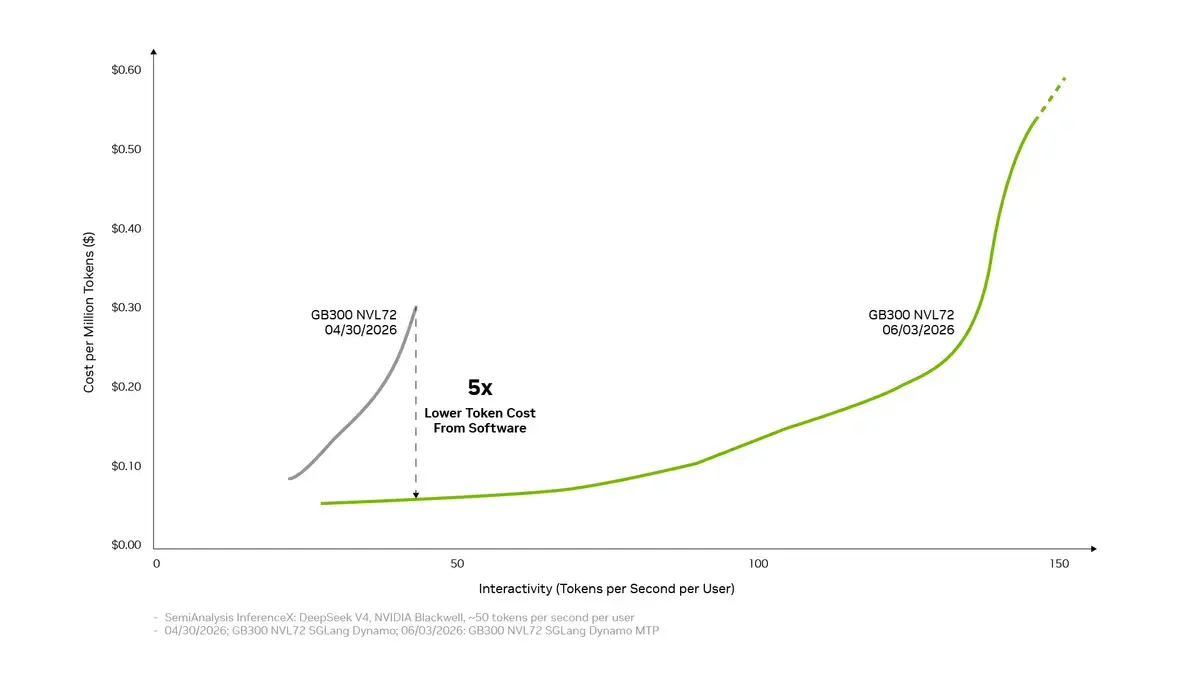
- NVIDIA utilized software-level optimizations on Blackwell GPUs to achieve a fivefold reduction in DeepSeek v4 token costs.
- The latest inference software stack increases system-level throughput capacity by up to 20 times.
- Industry leaders including Baseten, Cognition, and Together AI have integrated these advanced inference infrastructures into their production environments.
Software Optimizations Enhance Overall Performance
The core of NVIDIA’s recent success lies in a multi-layered software strategy designed to manage hardware resources with peak efficiency. By integrating production operations, application acceleration, and infrastructure accessibility, the company ensures that its Blackwell GPUs function at full capacity. This technical integration minimizes resource waste, which is particularly critical during the intense computational demands of deep learning processes. 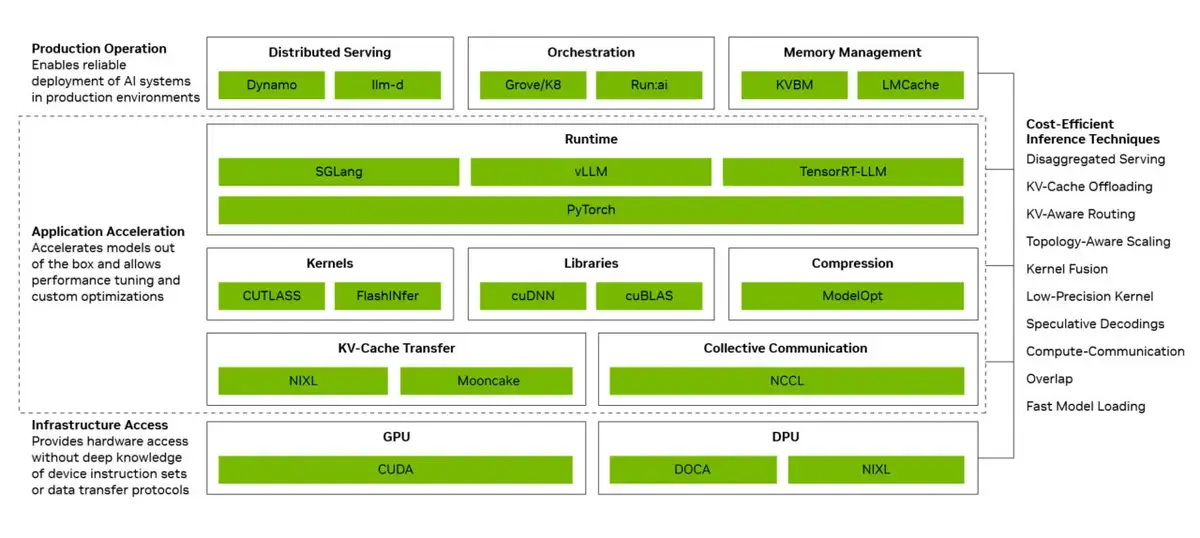
System-level integration fundamentally transforms the total cost of ownership for modern artificial intelligence projects.
The application acceleration layer provides developers with a high-performance environment while utilizing runtime optimizations like kernel fusion and compute-communication overlap to accelerate data processing. NVIDIA allows developers to achieve high-efficiency results using high-level software tools, eliminating the need to manually manage complex device-level instruction sets. This approach streamlines the development pipeline and allows teams to focus on scaling their models rather than debugging infrastructure limitations.
Industry Leaders Adopt Blackwell Architecture
Numerous technology companies have begun incorporating these latest software updates into their platforms to leverage improved performance metrics. Baseten recently announced that it achieved a 50 percent increase in tokens produced per second for the DeepSeek V4 Pro model by implementing the TensorRT-LLM library. Similarly, platforms such as Cognition and Deep Infra are utilizing NVIDIA’s pre-built inference frameworks to bypass the substantial burden of building custom infrastructure from the ground up. 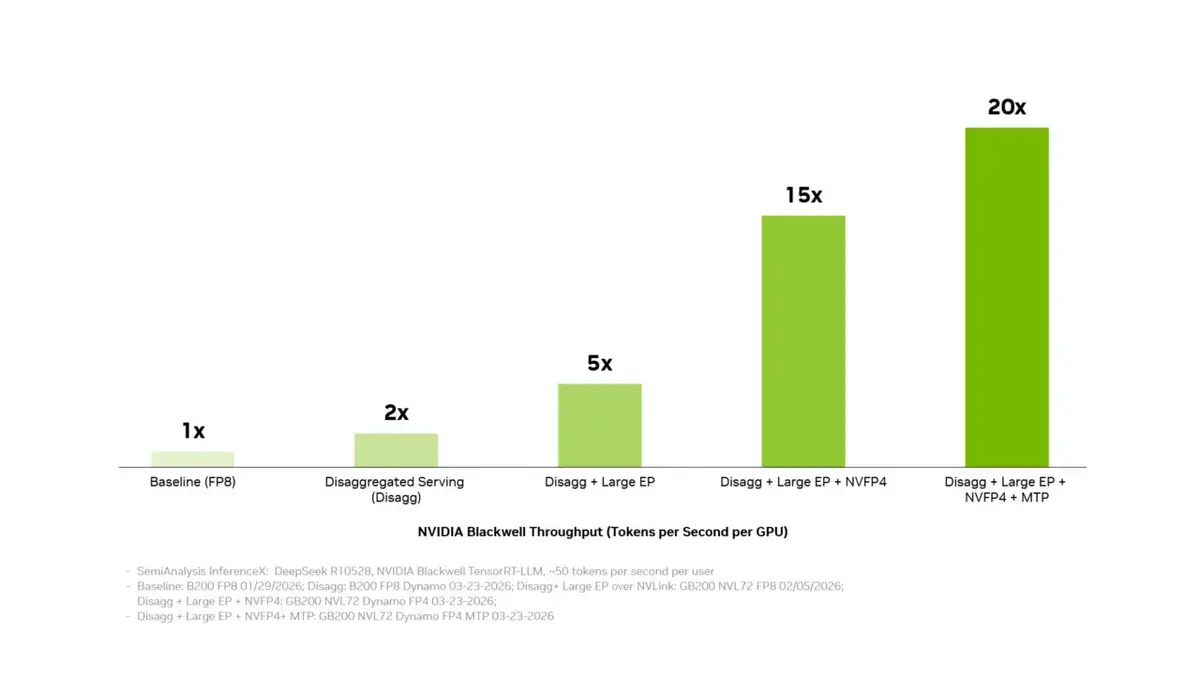
NVIDIA’s software-driven advantages directly influence the scalability of sophisticated artificial intelligence models.
Companies like Together AI are accelerating optimization processes for tools such as Cursor, resulting in significantly lower latency for real-time coding assistants. These collaborations illustrate how NVIDIA is building a comprehensive software ecosystem that extends far beyond simple hardware sales. By focusing on the entire inference stack, the company is ensuring that its hardware remains the default choice for developers worldwide. 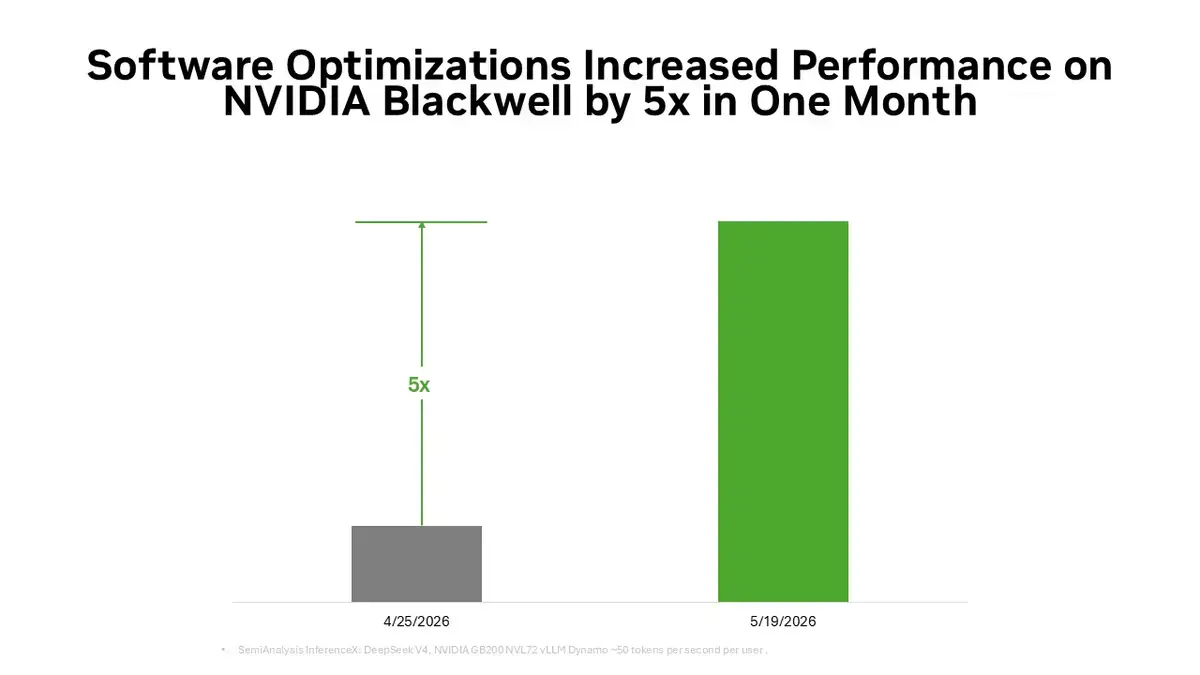
Efficiency-Driven Competition Accelerates in the Future
Technologies such as NVLink and NVFP4 provide additional benefits that prove the Blackwell architecture represents a revolution in efficiency rather than just a speed increase. The observed 20-fold increase in total throughput makes large language models (LLMs) significantly more commercially viable. NVIDIA’s strategic shift signals that high costs will no longer serve as a barrier for AI developers, but rather as an opportunity for rapid innovation.
How do you evaluate NVIDIA’s aggressive move to lower AI inference costs through software? Do you believe these optimizations will significantly accelerate the global adoption of advanced AI models? Share your thoughts with us in the comments section below.
Your comment has been submitted,
it will be published after approval.